
Nós, os seres humanos, podemos entender o conteúdo de uma imagem simplesmente olhando para ela. Percebemos o conteúdo de imagem e, automaticamente, sabemos se é possível ler o texto. Ou seja, é uma capacidade quase que involuntária – Olhar, ver a imagem, ler o texto (separando o que é texto e/ou figuras) e processar o conteúdo. Contudo, os computadores não funcionam da mesma maneira. Eles precisam de algo mais “concreto” e organizado de uma maneira que possam entender o conteúdo de uma imagem digital.
Mas o que é uma imagem para um computador?
Segundo Gonzalez, R. and Woods, R. (1992), uma imagem pode ser definida como uma função “f(x, y)”, onde o valor nas coordenadas espaciais “X” e “Y” corresponde ao brilho (intensidade) da imagem nessa coordenada.
A única forma de se representar uma imagem em um computador é quando ela está digitalizada tanto no domínio espacial como no das amplitudes.
Uma imagem digital é a representação numérica e discreta de um objeto, ou especificamente, é uma função quantificada e amostrada, de duas dimensões, geradas por meios ópticos, disposta em um grade padrão, retangular igualmente espaçada, quantificada em iguais intervalos de amplitude. Assim, uma imagem digital é um vetor retangular bidimensional de amostras de valores quantificados (Cordeiro (2002), Castleman (1996)).
Em outras palavras, uma imagem digital é (basicamente) um conjunto de três canais de cor. Também conhecidos como RGB (RED – GREEN – BLUE). O RGB pode variar seus valores internos entre 0 e 255. Logo, a “mistura” dos elementos gera uma imagem digital. Vale lembrar que, as menores unidades de uma imagem digital são denominadas Picture Element (Pixel). Um pixel é a representação numérica da luminosidade de um ponto da imagem.
Bem, agora sabemos o que é uma imagem digital (ou não). É nesse momento que entra o motivo de escrever e o OCR – “Optical Character Recognition” (Tradução Livre: Reconhecimento Óptico de Caracteres).
O motivo principal (além da curiosidade): Considere a preguiça como fator chave da evolução humana, okey?! Então… Quando o ser humano é motivado pela espírito da automação de algo, na real, o combustível é a preguiça. O ato fazer sempre a mesma coisa por um longo período de tempo é, literalmente, um saco. Agora imagine ter que redigitar documentos longos burocráticos por um longo período de tempo, imaginou?! É, você entendeu a motivação. Enfim, mas e a tecnologia?
Na prática, essa tecnologia (OCR) faz a leitura de um arquivo em imagem para identificar padrões e/ou transcrever textos que estão contidos em placas, publicidade, livros e/ou documentos manuscritos que devem ser convertidos em cópia digital. Embora nem sempre seja perfeito, é muito conveniente e torna muito mais fácil e rápido para algumas pessoas realizarem seu trabalho. (“Uhm… Interessante, não é mesmo?!”)
Mas e a aplicação na vida real?
Um exemplo muito comum de aplicação do OCR, mas que, ao mesmo tempo causa enorme dor de cabeça para os condutores, são os radares de trânsito. Eles possuem câmeras de alta sensibilidade que capturam fotos da placa dos veículos (em casos irregulares) e enviam os arquivos para um sistema que utilizará o OCR para extrair os números e letras da imagem que foi recebida.

No texto, para ilustrar o funcionamento do OCR, irei demonstrar o reconhecimento óptico de caracteres usando o Tesseract OCR.
Originalmente, o Tesseract foi desenvolvido na Hewlett-Packard Laboratories Bristol e na Hewlett-Packard Co, Greeley Colorado (1985 à 1994). Depois de algumas mudanças, foi portado para Windows em 1996, além de alguns upgrades em 1998. Contudo, só em 2005 o Tesseract foi liberado para a comunidade pela HP. Assim sendo, desde 2006 é desenvolvido/mantido pela Google.
Repositório no GitHub: https://github.com/tesseract-ocr/tesseract
Início dos trabalhos com Tesseract OCR
Para o exemplo de OCR, precisamos do Tesseract OCR. O processo de instalação se encontra no link: https://github.com/tesseract-ocr/tesseract/wiki
Para instalações no Windows, o executável pode ser baixado no link: https://github.com/UB-Mannheim/tesseract/wiki
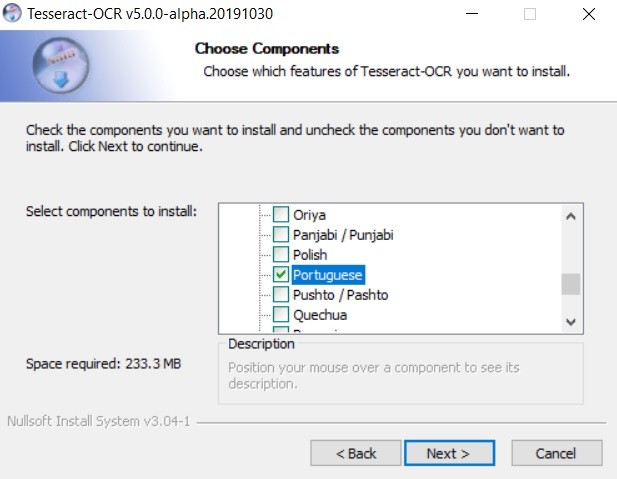
* É muito importante incluir na instalação o suporte à linguagem “portuguese”.
O funcionamento do exemplo depende, também, da Lib (biblioteca) do Tesseract para a linguagem Python (PyTesseract), que é uma “cápsula” (invólucro) do mecanismo Tesseract-OCR do Google.

Não vamos esquecer de criar um ambiente virtual (virtualenv), é claro – Só questão de segurança para não corromper sua instalação principal do Python. Ou seja, vamos isolar nosso exemplo em um ambiente virtual. Em caso de dúvidas, recomendo o post: https://pythonacademy.com.br/blog/python-e-virtualenv-como-programar-em-ambientes-virtuais
Show Me!!!
Para o simples script Python com OCR, a opção de uso de editor foi o Google Colab. Como usarei o Google Colab (mais fácil para rodar o exemplo), a instalação do tesseract será um pouco diferente do que citei acima. No “Colab” é necessário rodar o comando:
!sudo apt install tesseract-ocrA biblioteca Pillow, que é um “fork” (bifurcação) da PIL (Python Imaging Library) para lidar com a abertura e manipulação de imagens em muitos formatos no Python, também, será utilizada.
# Instalação de bibliotecas no Google Colaboratory.
!pip install Pillow
!pip install pytesseractCom a instalação do “tesseract-ocr” concluída e bibliotecas instaladas.
Importamos as bibliotecas instaladas. “Image” da biblioteca Pillow e da nossa biblioteca PyTesseract.
# Importando as bibliotecas instaladas.
from PIL import Image
import pytesseract* É necessário indicar o caminho do “tesseract” para o Google Colab.
pytesseract.pytesseract.tesseract_cmd = (r'/usr/bin/tesseract')Agora podemos criar uma função que obtém uma imagem e retorna o texto detectado na imagem.
Image.open() recebe uma string indicando um caminho válido de uma imagem (quando não especificado o diretório, a busca ocorrerá na raiz do seu arquivo de script) e retorna uma referência a um objeto em memória do tipo PIL.Image.
Pytesseract.image_to_string() recebe o parâmetro obrigatório “image”, e o opcional “lang”, isto informa ao tesseract que o alfabeto que ele está tentando reconhecer é o português (suportando acentos e cedilha), caso não especificado seu padrão é “eng”, inglês.
Atribuído o retorno do texto reconhecido para a variável “text_extracao”.
def img_core_file(imgfile):
"""
A função manipulará o processamento principal de imagens OCR.
- Usaremos a classe Image do Pillow para abrir a imagem e
o pytesseract para detectar a string na imagem.
- É muito IMPORTANTE que o valor “lang” esteja em português, pq o
valor padrão é inglês (Idem a instalação. Lembra?). Logo, afeta no
resultado de saída do texto.
"""
text_extracao = pytesseract.image_to_string(Image.open(imgfile))
return text_extracaoImagem de exemplo:

Em seguida, criamos uma função “img_core_file” que recebe um nome de arquivo e retorna o texto contido na imagem.
Com o valor extraído vem do retorno de uma função, estou invocação do “print”. Ou seja, chamando a função (img_core_file) dentro dele e passando a imagem que desejamos extrair o texto.
# Não esquecer de adicionar a imagem no drive - Se tiver usando o Google
# Colab
print(img_core_file('vaidarcerto.jpg'))Usando um ambiente local
No seu terminal (ou CMD no Windows), você pode criar um ambiente virtual e começar a importação das bibliotecas. Como, no momento, estou usando uma versão do Windows, o código pode ser um pouquinho diferente. Assim sendo, recomendo o link sobre os ambientes virtuais.
Processo no ambiente local é parecido com o do Google Colab:
Com a instalação concluída (Idem a instalação do Tesseract OCR acima.) e bibliotecas do Python instaladas, você cria a função (img_core_file) que obtém a imagem e retorna o texto detectado na imagem.
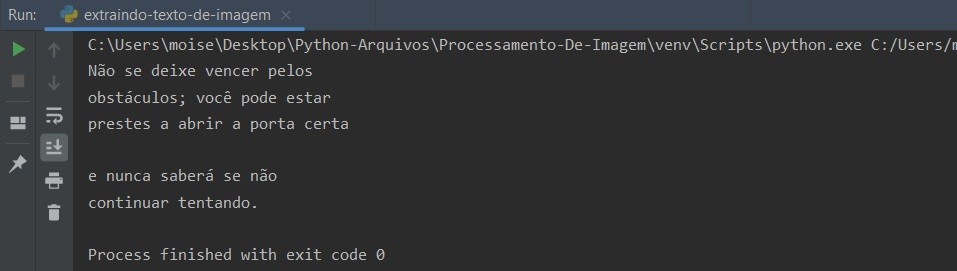
Na IDE PyCharm – Com seu diretório selecionado, crie um arquivo “.py” e chame do que quiser, eu chamei o meu de “extraindo-texto-de-imagem.py”. No mesmo diretório que o arquivo “.py” coloque uma imagem. Feito isso é só rodar o script e com o comando:
python extraindo-texto-de-imagem.py O resultado será:
Nas imagens com texto em inglês, a extração funciona?

# Não esquecer de adicionar a imagem no drive - Se tiver usando o Google
# Colab. Nesse caso o comando de upload de arquivos é:
from google.colab import files
uploaded = files.upload()Com a imagem em seu devido lugar, nós podemos passar o nome da imagem para a função e ela fará todo o trabalho de extração de texto.
print(pytesseract.image_to_string(Image.open('python-assert.png')))OUTPUT:
ASSERT STATEMENTS
IN PYTHON

Qualquer dúvida, o código está no Google Colab e GitHub:
- Google Colab: https://colab.research.google.com/drive/18CgSv9Mbw9o6Jah1byewmV547fwuztLz?usp=sharing
- No GitHub: https://github.com/MoisesTedeschi/Python/blob/master/Transcrição_de_imagem_em_texto_com_Python_e_Tesseract_OCR.ipynb
”Os problems… São os problems”
Como o Tesseract não é “bala de prata” (não resolve tudo e nem vai) é evidência de que o OCR nem sempre é 100%. Logo, é necessário/preciso de intervenção humana de tempos em tempos.
Existem de possíveis problemas listados no wiki. Várias etapas podem ser feitas para melhorar a fidelidade da Engine, tais como:
Redimensionamento, binarização, redução de ruídos, rotação/alinhamento das linhas e remoção das bordas. Nos casos mais simples, a resolução pode ser via retirada de bordas descartando a parte excedente do texto antes enviar ao pytesseract – Claro que existem outras possibilidades e bibliotecas, é claro. Por exemplo, o uso do OpenCV (detalhes no aqui), mas isso fica para outro papo.
Segundo o wiki acima, uma imagem elegível para uma extração mais fiel pelo tesseract-OCR deve possuir as seguintes recomendações:
- Dois canais de cores somente (preto e branco). Seja ela em escala de cinza (0≤ Vi≤ 255) ou então a imagem binarizada (Vi== 0 || Vi== 255). Vi=Valor de intensidade.
- Texto alinhado/padronizado e sem ruídos (gerados geralmente durante a etapa de binarização).
- Altura do box (espaço ocupado pelos caracteres) superior ao mínimo de 10px. Densidade ideal de 300dpi, ou proporcionais para o pressuposto acima. Possuir o texto extraível em um único padrão de alfabeto (ou idioma). Sem espaço inútil, considerado como bordas para o texto.
Still having problems?
Se você tentou, mas ainda está obtendo resultados de baixa precisão, peça ajuda no fórum, postando sua imagem que deseja extrair conteúdo.
Por fim…
No exemplo, nós nos concentramos na biblioteca PyTesseract. Contudo, existem outras Libs Python que podem ajudar na extração de textos de imagens. Por exemplo:
OpenCV: Pode extrair, também, textos de imagens, reconhecimento facial e afins.
Textract: Pode extrair dados de PDF’s.
Pyocr: Oferece mais opções de detecção, como frases, dígitos ou palavras.
Autores Citados
- Gonzalez and Woods (1992) GONZALES, R. C. WOODS, R. E. Digital Image Processing. University of Tennessee Perceptics Corporation, 1992.
- Cordeiro (2002) Cordeiro, F. M. Reconhecimento e Classificação de Padrões de Imagens de Núcleos Linfócitos do Sangue Periférico Humano coma Utilização de Redes Neurais Artificiais. Universidade Federal deSanta Catarina, 2002.
- Castleman (1996) Castleman, Kenneth R. Digital Image Processing. Upper Saddler River: Prentice Hall, Inc. 1996.
Deixe um comentário
Você precisa fazer o login para publicar um comentário.